project-proposal-2025
TaxMate: AI-Powered Australian Tax Assistant
Abstract
TaxMate is an intelligent tax preparation assistant designed to guide Australian taxpayers through lodging their tax returns. By leveraging LangChain for conversational AI, Neo4j for tax regulation modelling, and AWS for scalable deployment, TaxMate simplifies tax preparation through automated document processing, personalised deductions, and real-time calculations. The architecture prioritises scalability (handling seasonal peaks), extensibility (adapting to evolving regulations), and data accuracy (ensuring agent responses align with regulations), ensuring a reliable and comprehensive tax preparation experience.
Author
Adam Fittler (s4696807)
Functionality
The complete system provides a Guided Tax Interview, featuring a step-by-step user interface for tax data collection. This is complemented by Document Processing capabilities, which enable automated extraction from payment summaries, receipts, and various financial statements.
The system incorporates a comprehensive Tax Knowledge Graph Database (Current SOTA in RAG systems), serving as a repository of tax rules based on the official ATO documentation. Users benefit from Personalised Deduction Discovery, which identifies applicable deductions based on their specific circumstances and financial situation.
Throughout the process, the system offers Real-Time Calculation functionality, providing ongoing updates on tax liability and refunds as information is entered. This allows users to see how different inputs affect their final tax position.
User Stories
To further clarify functionality, here are two example user stories:
-
As a PAYG employee, I want to input my income and deductions through a guided interview so that I can complete my tax return quickly and accurately.
-
As a taxpayer with receipts, I want to upload and categorise my receipts so that I can claim all eligible work-related expenses.
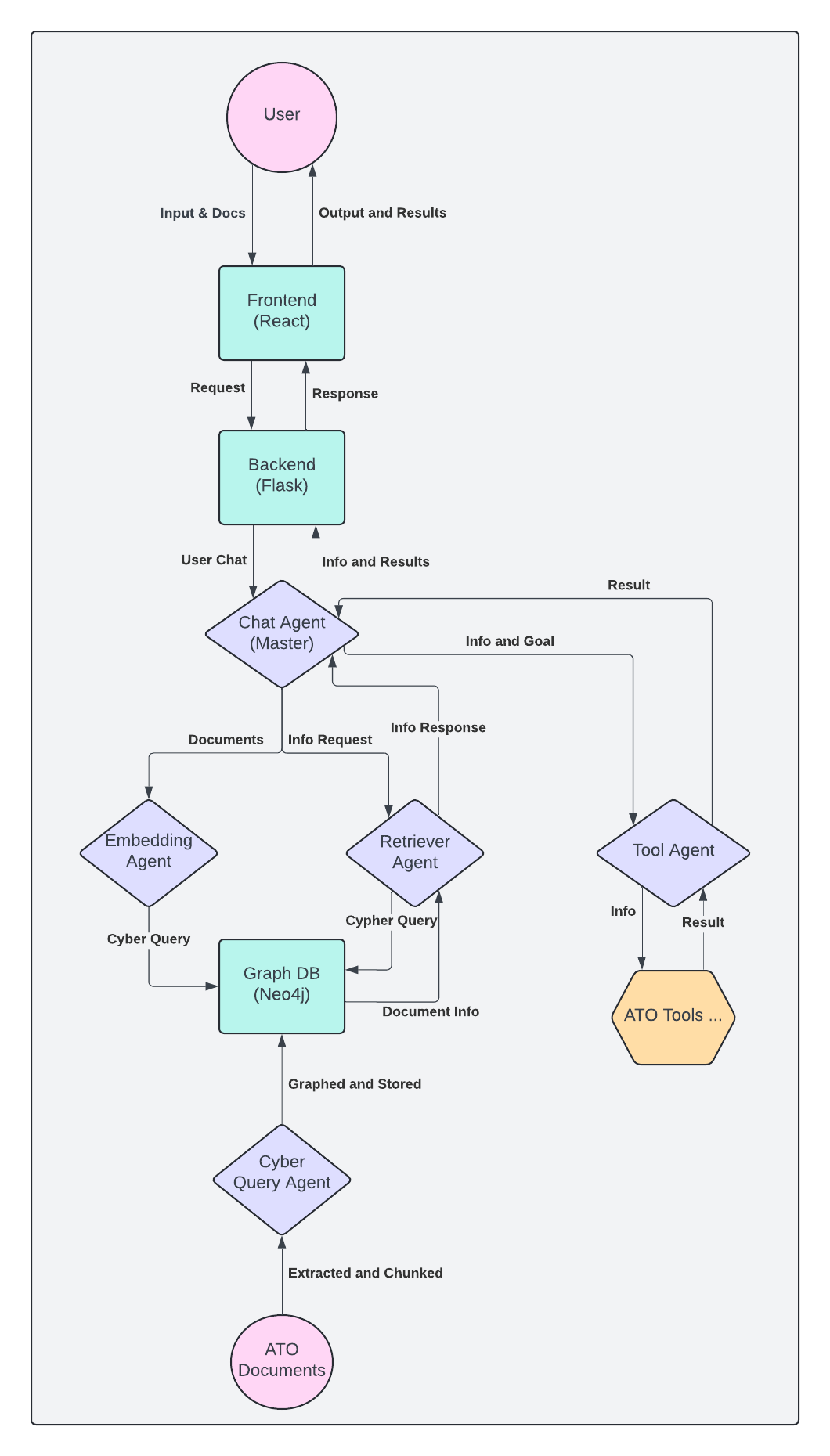
As seen in the rough architectural diagram above, the plan for the application is to leverage AWS instances to host the React application, backend Flask endpoint, and the Neo4j graph database. Each component will be dockerised to ensure environmental consistency. For the graph database, a Neo4j database docker container on an EC2 instance is leveraged instead of AWS Neptune. This decision has been made to prevent vendor lock-in issues, allowing for greater flexibility in the future. However, Neptune could be used if data backups become a critical requirement.
The main value of the application will come from the agentic workflow in the backend. This will leverage the LangChain, LangGraph, and Llama Index libraries, as well as the hierarchical agent pattern (implemented via LangGraph supervisor abstraction), to create a powerful and streamlined agentic workflow. The agents will also have access to the Neo4j graph database and other custom tools, enabling them to retrieve vital information and perform complex tax calculations when necessary.
Furthermore, the plan is to move all ephemeral functions to AWS Lambda functions for better cost optimisation and scalability. This serverless approach will allow the system to only pay for actual computation time rather than maintaining constantly running instances for functions that are called infrequently.
Scope
The project will implement a Simplified Tax Interview Framework, providing a streamlined interview process covering basic income and common deductions. This framework will primarily focus on PAYG employees with straightforward tax situations and include basic user progress tracking via local storage.
The team will develop Limited Tax Knowledge Integration through a small-scale Neo4j graph covering essential 2024-2025 individual tax rules, with an emphasis on common deductions such as work-related expenses and donations. For document handling, the system will employ manual entry forms for income statements alongside simple receipt upload and manual categorisation capabilities. The Calculation & Deployment aspects will include basic tax estimation for standard returns, utilising AWS deployment to ensure high uptime and scaling potential.
Quality Attributes
Scalability
Scalability is critical for handling the massive seasonal load variations that occur during the July-October peak tax filing season. The team will measure this attribute through response time consistency, aiming for less than 3 seconds per query under 500 concurrent users. This target aligns with industry standards for interactive applications, ensuring a responsive user experience. Additionally, they will evaluate the cost per return during peak versus off-peak periods and assess AWS auto-scaling speed with a target of resource adjustment within 5 minutes of demand changes.
Extensibility
Extensibility is crucial for accommodating annual tax regulation updates and incorporating new deduction types. The team will measure this by tracking the time required to implement rule changes, with a target of less than 1 week. This aligns with Agile development principles, which recommend short iterations for rapid adaptation. They will also assess code reuse percentage for new tax scenarios, aiming for greater than 70% reuse. High code reuse improves maintainability and reduces development effort.
Data Accuracy
Accuracy of data is critical to ensure users can trust the agent’s knowledge and recommendations. This will be evaluated using precision and recall metrics for the top 5 retrieved documents in the RAG (Retrieval-Augmented Generation) system. This aligns with common industry and research practices for evaluating RAG systems.
Evaluation
Scalability Testing
The approach to Simplified Load Testing will involve deployment on AWS Free Tier EC2 instances and the use of open-source tools like JMeter to simulate 10–50 concurrent users. This small-scale testing allows the team to identify performance bottlenecks and resource constraints without incurring significant costs. They will measure response times and system resource utilisation throughout these tests and document performance bottlenecks for future scaling considerations.
Success Metrics:
-
Average response time under 3 seconds.
-
CPU and memory utilisation below 80% under peak load.
Extensibility Testing
For extensibility testing, the team will implement a Limited Tax Rule Update Demo by modifying the Neo4j graph to include one new deduction category, documenting the process, and estimating time requirements for larger-scale updates. This demonstrates the system’s ability to adapt to regulatory changes. They will also conduct a Mini-Scenario Implementation by adding support for a single new user scenario, such as basic HECS-HELP debt handling, and measuring and documenting the development effort required.
Success Metrics:
-
Time to implement a new deduction category: less than 1 week.
-
Code reuse percentage for new scenarios: greater than 70%.
Data Accuracy Testing
For Data Accuracy testing the team will evaluate the precision and recall metrics for the top 5 retrieved documents in the RAG (Retrieval-Augmented Generation) system. Precision measures the proportion of relevant documents retrieved, while recall measures the proportion of all relevant documents that are successfully retrieved. Here as accuracy is the focus we have a higher standard for the precision as opposed to the recall hence the differing test criteria.
Success Metrics:
-
Top 5 Retrieved Document Precision: 80% or higher.
-
Top 5 Retrieved Document Recall: 60% or higher.