project-proposal-2025
SuperRepo
Abstract
When developing software, a well documented repository is crucial for planning and communicating project progress effectively. SuperRepo enhances version controlled repositories such as Github, by automatically generating detailed documentation using open-source LLMs. It integrates with version control systems to ensure documentation stays up-to-date as projects evolve.
SuperRepo offers potential expansion, including visual representations and recommendations for project improvement, feature development, and restructuring. Its design is reliable, modular, and scalable, providing an open-source solution for accurate generative documentation and more.
Author
Name: Kintaro Kawai
Student number: 46985703
Functionality
It’s essentially an AI-powered wiki that is synced to a projects version control which allows it to write and update documentation on every commit.
Code Base Documentation:
- Traverse and scan any code base to map out its structure to document each component of the code base.
RAG Model and Vector Database:
- Implement a RAG model that stores project contents in a vector database. This allows the LLM to contextualise the contents for real-time document generation.
Wiki Interface:
- Provide a clear sidebar to navigate between all components within the application.
- Include basic wiki editing features such as text changes, layout, tables, etc.
- Support publish, draft, delete, edit, and read-only interactions with pages.
- Allow direct access to selected sections of the code base.
Version Control Sync:
- Ensure the wiki documentation updates in real-time when changes are made on Git.
- Display a comparison log of documentation changes corresponding to Git versions.
Third-Party Authentication:
- Utilise existing authentication services like Github and Gitlab.
- Only allow wiki creation if an admin of the repository accepts access, ensuring one wiki per repository.
Database Design:
- NoSQL Database: For raw text documentation, providing flexibility and scalability.
- SQL Database: For relational data, ensuring data consistency and integrity.
- Vector Database: For storing and querying vector embeddings used by the RAG model.
Dashboard for Multiple Repositories:
- Provide a dashboard/interface to manage multiple repositories, ideal for companies running microservices.
Visual Diagrams and Tables:
- Offer the ability to generate visual diagrams and tables to explain code base functionality and flow.
LLM Model Selection:
- Allow users to select different LLM models based on expected accuracy and speed.
Quality Assurance and Feedback:
- Enable testing of the RAG model and SuperRepo outputs to ensure reliable documentation.
- Allow users to provide feedback on LLM outputs, recording input, output, and satisfaction scores to fine-tune prompts.
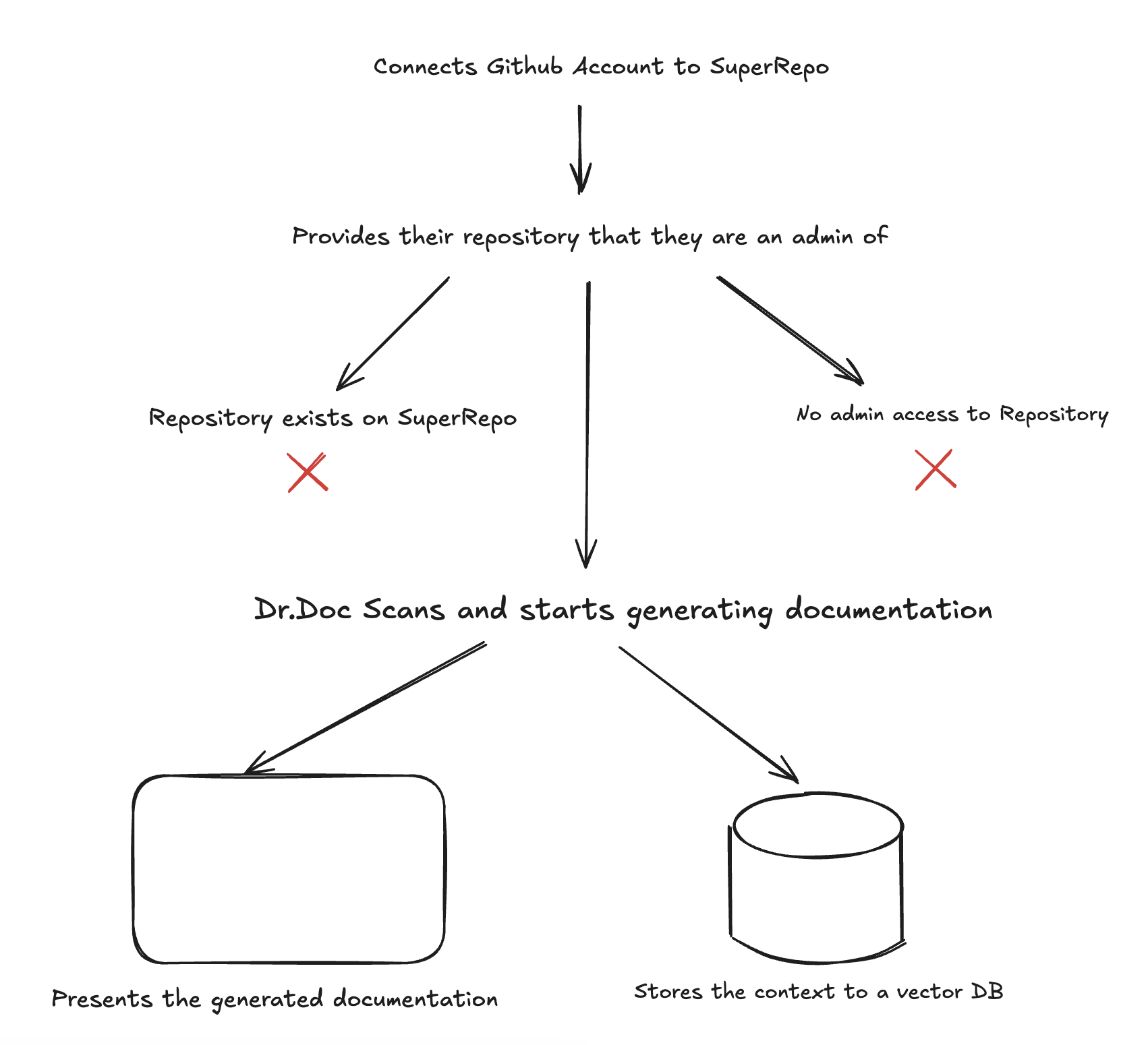
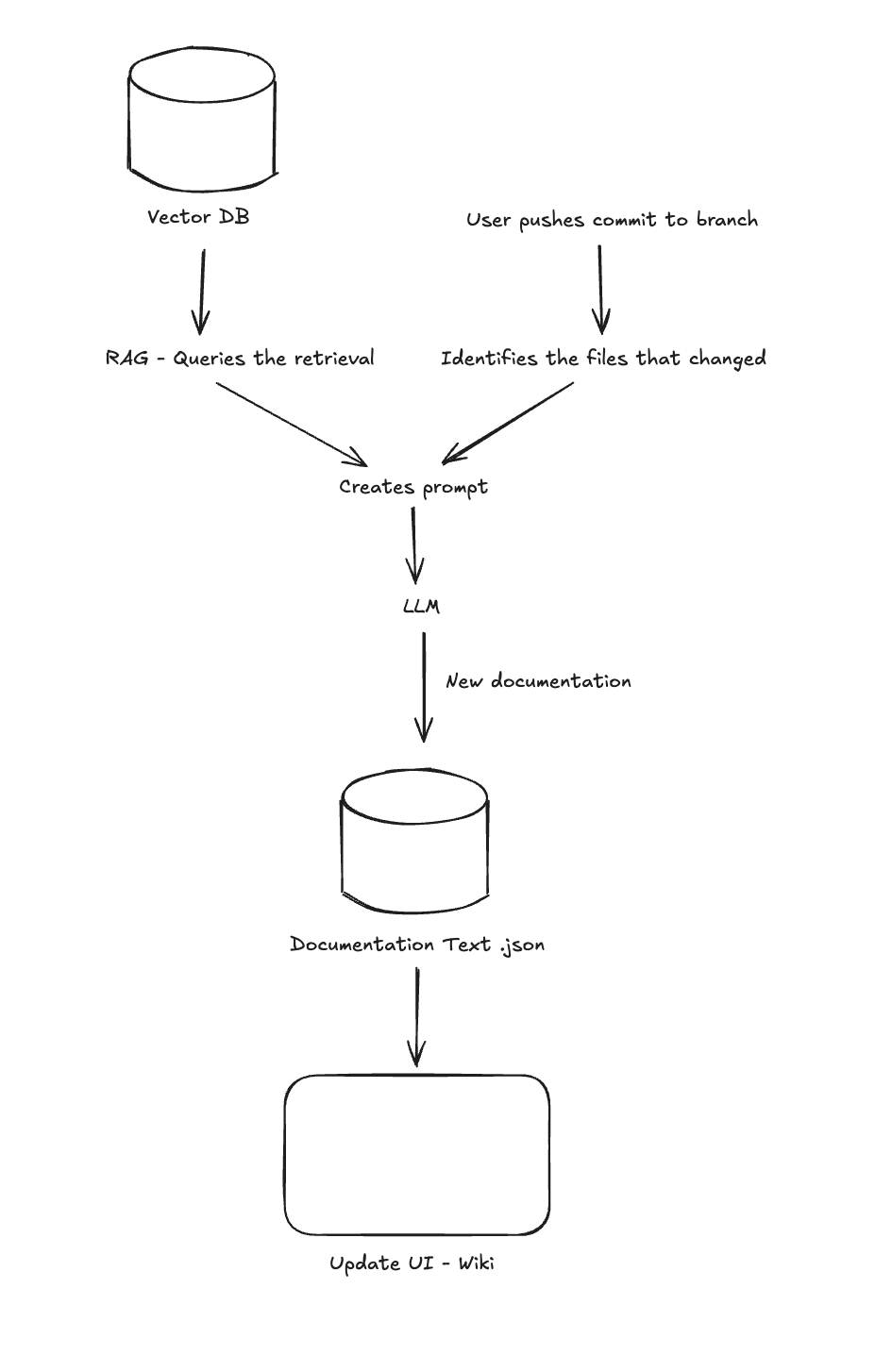
Two example flow of SuperRepo - (left) a new user’s interaction, and (right) a user making a change:
 |
 |
Scope
Github Integration and Authentication:
- Users log in with their Github account to view all SuperRepo projects they are part of.
- Only admins of the repository can authorise the creation of a SuperRepo wiki.
- Documentation for private repositories should not be accessed if a user isn’t logged in or does not have access to the repository.
Textual Documentation Generation:
- The MVP will generate textual documentation using a LLM of choice.
- Documentation updates dynamically based on changes to the code base.
Contextual Information Management:
- Use a vector database to store contextual information.
- Implement a RAG model to provide the LLM with updated context.
Version Control and History:
- Users can view previous changes to documentation similar to Git version control.
- Documentation specifies the Git version being viewed.
Wiki Interface:
- Implement a common UI design with a sidebar for navigation.
- Users can access the direct code base on Github from the documentation.
- Support publish, create, draft, update, delete, and read-only interactions with the wiki.
Repository Scanning:
- Load a new repository by traversing and scanning the entire existing code base to create context for LLM document generation.
Public Deployment:
- Deploy SuperRepo as a web application, allowing public access to the generated documentation.
- SuperRepo should be accessible via a URL and the individual documentation should also be accessed using a URL. e.g. superrepo.com/myreponame
Database Design:
- NoSQL Database: For raw text documentation, providing flexibility and scalability.
- SQL Database: For relational data, ensuring data consistency and integrity.
- Vector Database: For storing and querying vector embeddings used by the RAG model.
Quality Attributes
Reliability
Reliability is a crucial quality attribute for SuperRepo, as it ensures that the generated documentation is accurate and informative. The effectiveness of the prompting phase significantly impacts the reliability of the outputs. By using well-crafted prompts with the latest models, SuperRepo can produce highly accurate results.
To measure reliability, SuperRepo can record input, output, and satisfaction metrics through behavioral analysis and manual human evaluation. This process provides insights into how well the prompts are constructed, allowing for improvements to enhance the overall reliability of the system.
Modularity
Modularity is another key attribute, enabling SuperRepo to evolve beyond documentation generation. By understanding the context of the entire project, SuperRepo can be extended to support additional features such as chat systems that answer code-related questions or provide generative recommendations for improvements.
To achieve and measure modularity, SuperRepo should be tested against diverse scenarios. Designing a versatile API that can handle different prompts and use cases is essential. This API should not only support documentation but also be reusable for other use-cases, such as chatbots or recommendation systems.
Scalability
SuperRepo’s database architecture combines NoSQL, SQL, and vector databases to mitigate scalability issues. NoSQL handles raw text documentation, while SQL manages relational data. The vector database is used for the RAG model by storing and querying vector embeddings.
To ensure scalability, SuperRepo will implement sharding to distribute data queries, and load balancing to manage traffic. These strategies should enable the system to handle large data volumes of both structured and unstructured data effectively.
Evaluation
Reliability
To evaluate the reliability of SuperRepo, we will record input, output, and satisfaction metrics through behavioral analysis and manual human evaluation. This process will assess the accuracy and informativeness of the generated documentation, providing insights into how well the prompts are constructed for the LLMs. Continuous feedback will be used to refine prompts and improve the overall reliability of the generated documentation.
Modularity
Modularity will be evaluated by testing SuperRepo against diverse scenarios to assess its ability to support additional features beyond documentation generation. It will be accessed by how easily new features can be integrated into the system without disrupting existing functionality, ensuring that SuperRepo can evolve efficiently.
Scalability
Scalability will be evaluated by continuously monitoring system performance under varying loads to ensure it maintains high performance and scalability. The effectiveness of sharding, replication, and load balancing strategies will be assessed by simulating large traffic using stress testing software such as JMeter, as well using tools like Grafana or Prometheus to monitor throughput such as CPU usage, memory usage, and request rates.
Word Count: 1107 words