project-proposal-2025
LegalEase🎓
Abstract
LegalEase is a web-based AI-powered legal assistant platform designed to streamline legal research for lawyers, interns, judges, and legal scholars. It uses a Retrieval-Augmented Generation (RAG) pipeline with large language models (LLMs) which aims to reduce the manual burden of analyzing lengthy legal documents and precedents. Users can upload documents and ask questions in a ChatGPT-style interface, receiving detailed answers backed by relevant sources. This approach is crucial because LLMs alone often produce partially incorrect or outdated legal answers ; by grounding the AI’s output in authentic statutes and case documents, LegalEase mitigates hallucinations and ensures higher accuracy. By combining AI with authoritative legal databases, LegalEase provides accurate summaries, pertinent laws, and case references through a secure, user-friendly chat interface.
Author
Name: Aniket Gupta
Student number: 48240639
Functionality
If fully developed, the LegalEase platform would offer in these suites to assist in legal research and analysis:
Document Summarization: Automatically generate concise summaries of lengthy legal documents, contracts, and annexures, highlighting the key points and obligations.
Statute/Regulation Retrieval: Fetch relevant sections of government laws, statutes, or standards related to a user’s query or an uploaded document (for example, pulling up a cited Act or regulation for quick reference).
Case Law Cross-Referencing: Identify past judicial cases (precedents) related to the query or document context, providing brief summaries of those cases and noting their relevance.
Legal Text Insights: Quote definitions or explanations from law books and authoritative commentaries to clarify complex legal jargon or concepts in the material.
Interactive Q&A Interface: Allow users to ask questions in a chat interface about the documents or legal topics and receive detailed, context-aware answers (with references to source materials) in a conversational manner.
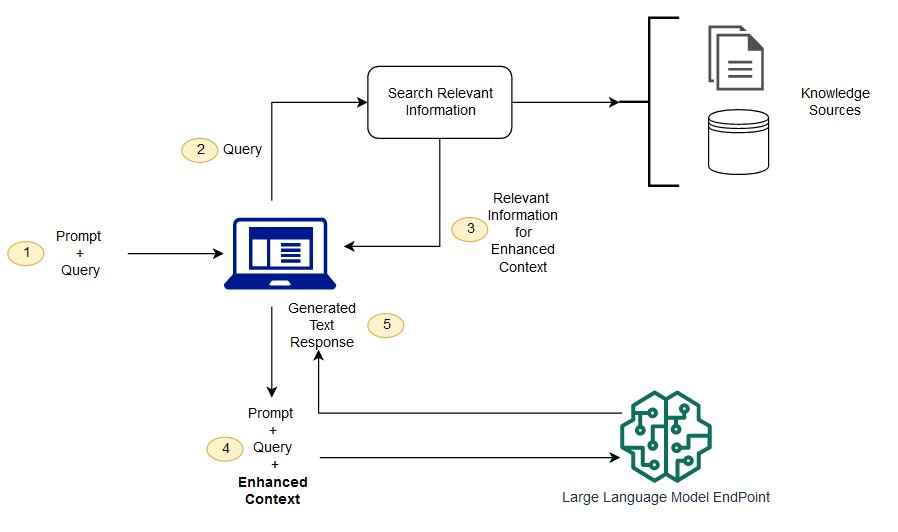
Figure: High-level RAG architecture for LegalEase. A user’s query (plus any uploaded document text) triggers a search through the legal knowledge base (laws, case archives, textbooks) for relevant snippets. These snippets are then provided to the LLM alongside the query, enabling it to generate a response that is grounded in the retrieved content. Frameworks like LangChain or LangGraph help orchestrate these steps in a coherent pipeline.
Scope
The minimum viable product (MVP) will focus on core features that can be delivered within the academic timeline, providing a functional demonstration of LegalEase:
Document Upload & Summary: Implement file upload (PDF or text) and use the LLM to generate an automatic summary of the document’s content.
Basic Q&A on Documents: Enable users to ask questions about the uploaded document and get answers. The assistant will utilize the document text (and a small set of reference materials) as context for the LLM, demonstrating the RAG approach on a limited scale.
Sample Legal Knowledge Base: Include a lightweight database of legal materials (e.g. a few key statutes or case briefs) to support the retrieval mechanism. For the MVP, these will be pre-loaded and indexed (using a vector store like FAISS or Chroma via LangChain) for semantic search.
Chat Interface Prototype: Develop a simple web interface (e.g., with Streamlit or Flask) where users can interact with the chatbot, upload documents, and view answers with cited references.
Security Basics: Apply fundamental security measures: enforce HTTPS for any web service, handle file storage carefully (e.g., in memory or protected locations), and do not retain uploaded data longer than necessary. Full authentication or advanced encryption might be deferred, but the design will consider these needs.
Quality Attributes
We focus on the following critical quality attributes, each with clear, testable definitions:
Security
Given the sensitive nature of legal documents, security is a top priority. All data transmissions will be encrypted (HTTPS) and documents stored with access controls to prevent unauthorized viewing. The platform should have no critical vulnerabilities in testing (it must pass checks for OWASP Top 10 risks), and it must protect client confidentiality at all times .
Scalability
LegalEase must handle increasing workloads (more users and larger documents) without performance degradation. A measurable goal is that the system supports, for example, 20 concurrent users processing 100-page documents each while keeping average response time under 10 to 15 seconds. Architectural choices like using vector indexes and streaming responses ensure that as data volume grows, the system can scale horizontally by adding computing resources.
Reliability & Availability
Legal professionals need the assistant to be dependable and consistently accessible. Reliability means the system functions correctly and handles errors gracefully (e.g., if an input is invalid or an external API fails, the user receives a proper error message instead of a crash). We target a 99% uptime equivalence, meaning the service should rarely be down. For the MVP, this translates to no unexpected crashes during extensive testing (e.g., surviving 100+ sequential query tests). The design will include basic monitoring or logging to help quickly identify and recover from any failure.
Modularity (Maintainability)
The system is designed in a modular fashion, with loosely coupled components (frontend UI, backend services, retrieval module, LLM integration). This makes it easier to maintain and extend; for instance, the LLM or vector database can be swapped out with minimal code changes. We expect that adding a new data source or replacing a component requires changes only in that module’s code. Using frameworks like LangChain/LangGraph further enforces a component-based pipeline structure , enhancing modularity.
Evaluation
To validate the quality attributes, we will employ the following strategies:
Security: Run security scans (e.g., OWASP ZAP) on the web application to detect vulnerabilities (XSS, injection, etc.). We will also attempt to bypass protections (for example, trying to access an uploaded document without proper credentials) to verify that access control is enforced. The goal is to find no serious issues; if any are found, they are fixed and the test is repeated until the system passes all major security checks.
Scalability: Use a load-testing tool (e.g., Locust) to simulate multiple users and measure performance under load. We will increase concurrent requests and document size while monitoring response times and system resource usage. The criteria are met if response times stay under the target threshold (e.g., <5 seconds) at the expected load (20 simultaneous users with large documents) without errors or timeouts.
Reliability: Run a suite of automated tests covering normal and edge cases (e.g., invalid file formats or extremely large inputs) to ensure the application handles them gracefully. Reliability is confirmed if the system remains stable and responsive throughout testing with no crashes. If a component does fail, it should fail safely—for example, by returning an error message instead of hanging or crashing.
Modularity: Perform a targeted refactor to swap out one component (for instance, replace the vector database or change the LLM API) and observe how localized the required code changes are. If the replacement can be done by modifying only the relevant module or configuration (with minimal adjustments elsewhere), it demonstrates high modularity. This experiment, along with a brief code review of component interfaces, will indicate if the architecture supports easy maintenance and extension.