project-proposal-2025
DriveVision
Abstract
As the autonomous driving industry continues to gain prominence, the need for reliable, user-friendly systems capable of real-time processing and analysis of automotive video streams has become increasingly critical. However, universally accessible and affordable solutions remain scarce, particularly for small startups facing high overhead costs and substantial development hurdles.
DriveVision addresses this gap as an innovative, web-based platform seamlessly integrating multiple advanced computer vision models to deliver instant and comprehensive analysis of vehicle camera feeds by performing various fundamental cv tasks such as depth mapping, object detection and segmentation, in which users can easily choose to turn on or off those features at any times.
The system emphasizes on scalability, modularity, extensibility, security as key attributes through its microservice-based architecture, as key attributes to ensure success of this project
Author
Name: Qinlong Zhang
Student number: 48370161
Functionality
Overview
Our system will provide API for the users, in which verified users can securely transmitted its video stream into our system
and get real time analysis data back such as segmentation data, depth data, and 3D object detection data back. User can of course
choose which data they want by turning on or off some analysis via button.
Users can also view those data overlay on top of videos in real time by selecting the needed overlay via buttons.
The general workflow as follows
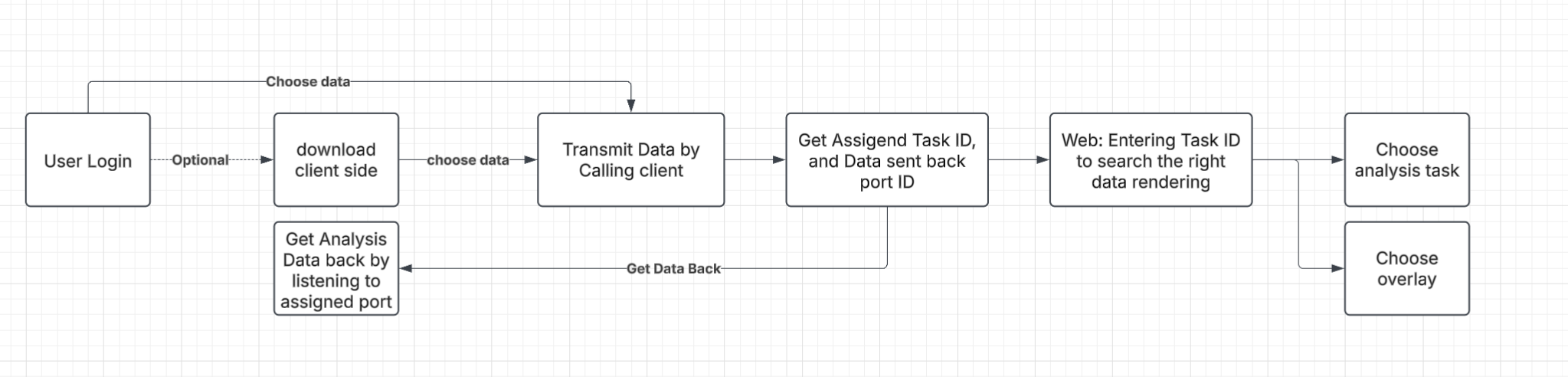
Features
-
Users shall need to login into the system for accessing service
-
users will download the client side app, to securely transmit and receive data, the users must transmit data by calling its function and receive data by listening to the app assigned port
-
Once data stream is transmitted, users can view the real time video rendered on the web, on the CV task pane, users can choose which task they want to perform. User are warned that once they turn off this task, the corresponding analysis service will be paused.
-
Users can also choose the overlay on the CV overlay pane, but users are warned that the “turned-off” cv task’s corresponding overlay will be inactive
-
User will get analysis data such as segmentation data back from the client side by listening to the assigned port
-
User can transmit multiple data stream by calling the client side function multiple time and get the assigned ID back, User can also view each data stream on Web by searching the assigned ID on the web page.
-

Model

Scope
The scope for the minimal viable product is
- Web Service: Use Django framework to build web application deployed on container that support login, download, rendering video and overlay(use react REACT framework) , receive data stream via api(web socket), send data stream via api(web socket). support search, dropdown and button so user can search and select analysis task
- Client: A simple binary executable for linux (run via command line) that can receive data stream via socket and sent to server via url api call(web socket), E2E encryption, sent data stream via port, write important output to terminal (such as task ID, port)
- In order to host AI analytical power, server with GPU accessed must be obtained to perform analysis, each task will be assigned a server, and will contact via api. For simplicity and minimal implementation, we use open-sourced code release on github written in pytorch as listed in model section that do only inference
Quality Attributes
The Quality attributes that are important for this project are scalability,modularity, extensibility. While, the security is a important feature, it will not be major focus as it can be easily integrated during in the implementation phase. The three attributes importance are ranked in a sequential order with the most important attribute on the top, and least important on the bottom
- Scalability:
Scalability is also extremely important, given that CV inference is a computationally heavy task. When there is huge influx data to be processed at same time, it is infeasible for a single node to give a real time response. However vertical scaling requires expensive overhead, which may not be instantly available, thus we primary rely on the horizontal scaling to dispatch tasks to different nodes for inference, so users won’t have to wait long time to wait for the system to response. This is crucial as automatic driving have extreme high level requirements for low latency reliable inference, otherwise car incidents may happen.
- Modularity:
Modularity is very important attributes. That is because many components of this project such as CV analytical jobs, Login Tasks, Rendering Tasks, Data stream Exchange, are self-contained and can be independently developed, deployed, and updated provided given that the design is good enough. Given that limited time this project is available, concurrent development, deployment and update is important. Besides, Self-contained design is more robust as one component crash won’t propagate to the who system. The separation of functionalities also simplify the troubleshooting, maintenance, and future integration, which is also important. The decoupling design also enable extend new features functionalities much easier.
- Extensibility:
Extensibility is worth noting attributes. Given the fast evolution of AI, when new technologies emerges we want to quickly integrate them into our system even they are completely different from traditional ones, instead of only able to replace existing models. This will make our project remain competitive even in the future and evolve over time to adapt more and more user requirements
We made such trade off as low latency is most important for this project; a delayed process can result in serious safety hazard. Thus we put scalability on the top. Modularity is second, as we must guarantee the delivery the project in a fixed timeline with limited human power and resource. The extensibility is least important,as even it is not likely we will continue to work this project in the future, but we want to make it easy for us continue developing
Evaluation
- Scalability:
we will do a pressure test to see, the amount of concurrency one inference node can handle by checking its process time, CPU and Memory consumption. Thus we can determine the best load balance strategies to dispatch inference tasks. We will write automatic scripts to test limits of single inference node and results will be benchmarked including cpu consumption, memory consumption, and latency. We will also write scripts to test the entire inference service by starting increasing the number of concurrent data streamed and benchmarked the results, especially latency.
- Modularity:
Group discussion and architecture review will be made to determine the tight coupling that may hinder the modularity. Fault isolation test will be conduct to ensure a single module failure will not not crash the whole system. Unit testing ensure each module achieve its own assigned functionalities. Integration testing ensure that the module work smoothly with defined API and interface
–Extensibility
We will measure how easy/hard it is to integrate new analytical tasks using existing architecture. Sample analytical tasks will be procured for testing purpose such as VLM, etc. We will measure how many new modules have to be added, how many modules have to be updated, and how many module will be impact.